Once we have clear the NUMA concept, let´s go review the use on VMware.
( Part 1/2 http://virtualshocks.blogspot.com.es/2013/09/dou-you-kow-what-numa-is-really-part-1.html )
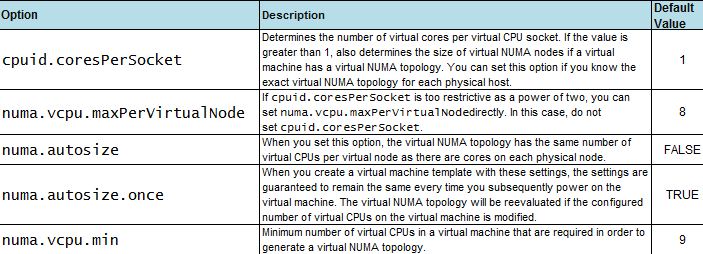
NUMA topology is avaliable on VMware vSphere 5.0 and later, hardware version 8 and later, and it´s enable by default when the virtual CPU is greater than 8, but it can be disabled or modify using advanced options (to enable vNUMA on 8 way or smaller VMs, modify the numa.vcpu.min setting) :
When CPU affinity is enable on a virtual machine, it´s treated as a NON-NUMA client and gets excluded from NUMA scheduling. It means that the NUMA scheduler will not set a memory affinity for the virtual machine to its current NUMA node and the VMkernel can allocate memory from every available NUMA node in the system. It wil increase memory latency and probabbly the value %RDY will get higher.

An example how NUMA (or vNUMA) works:

With NUMA enable, the Virtual Machine will get vCPU from the same NUMA node (it is, from the same socket)
But.... what´s about the best practices?
1-NUMA-nodes: take your time and the sockets features carefully because some physical cpu´s are composed with 2 underlying sockets. For example some ADM opteron wich have sockets with 12 cores are composed inside with 2 sockets and 6 cores each. It is, a server with 4 sockets 12 cores each.... are a 8 NUMA nodes and not 4.
2-The "default" config on a new VM is "cores per socket" equal to 1, it means that vNUMA is enabled and let the virtual topology to present the best performance to the VM.
3-If the number of "cores per socket" needs to be changed (for licensing purposes for example) the vNUMA will not apply the best config to the VM and will affect to performance. Only you choose a right combination with the vCPUs and cores per socket mirroring the physical NUMA topology on your server (review your NUMA-nodes config)
4-Cluster and DRS or vMotion: "One suggestion is to carefully set the cores per virtual socket to determine the size of the virtual NUMA node instead of relying on the size of the underlying NUMA node in a way that the size of the virtual NUMA node does not exceed the size of the smallest physical NUMA node on the cluster. For example, if the DRS cluster consists of ESXi hosts with four cores perNUMA node and eight cores perNUMA node, a wide virtual machine created with four cores per virtual socket would not lose the benefit of vNUMA even after vMotion. This practice should always be tested before applied. (VMware transcript) "
But.... what´s about the best practices?
1-NUMA-nodes: take your time and the sockets features carefully because some physical cpu´s are composed with 2 underlying sockets. For example some ADM opteron wich have sockets with 12 cores are composed inside with 2 sockets and 6 cores each. It is, a server with 4 sockets 12 cores each.... are a 8 NUMA nodes and not 4.
2-The "default" config on a new VM is "cores per socket" equal to 1, it means that vNUMA is enabled and let the virtual topology to present the best performance to the VM.
3-If the number of "cores per socket" needs to be changed (for licensing purposes for example) the vNUMA will not apply the best config to the VM and will affect to performance. Only you choose a right combination with the vCPUs and cores per socket mirroring the physical NUMA topology on your server (review your NUMA-nodes config)
4-Cluster and DRS or vMotion: "One suggestion is to carefully set the cores per virtual socket to determine the size of the virtual NUMA node instead of relying on the size of the underlying NUMA node in a way that the size of the virtual NUMA node does not exceed the size of the smallest physical NUMA node on the cluster. For example, if the DRS cluster consists of ESXi hosts with four cores perNUMA node and eight cores perNUMA node, a wide virtual machine created with four cores per virtual socket would not lose the benefit of vNUMA even after vMotion. This practice should always be tested before applied. (VMware transcript) "


